Multimodal AI Lab
A symphony of senses in the digital realm
Raison d'être
In daily life, people do not rely on only one sense. We look, listen, speak, move and react with our body and emotions at the same time.
Multimodal AI is about giving computers the similar ability: to learn from many kinds of information together instead being fragmented as just text or a single image.
When you read "What A Happy Sunny Day!", maybe you picture a bright sky, listen to cheerful birds, or feel the warmth on your skin. Each of these is a different way to experience the moment. Most AI can only focus on one thing at a time, like just showing you an image or reading the sentence. That's "unimodal AI", it handles only one type of information.
Now imagine if AI could take in all these experiences together to see, hear, and sense just like we do. That's the power of Multimodal AI, where technology understands the world through many streams of information all at once.
- •Humans are multimodal
- •Collecting multimodal data though essential but is difficult
- •India-Centric data collection for multimodal AI for the first time
- •Perfecting the synchronization techniques is the key to be mastered
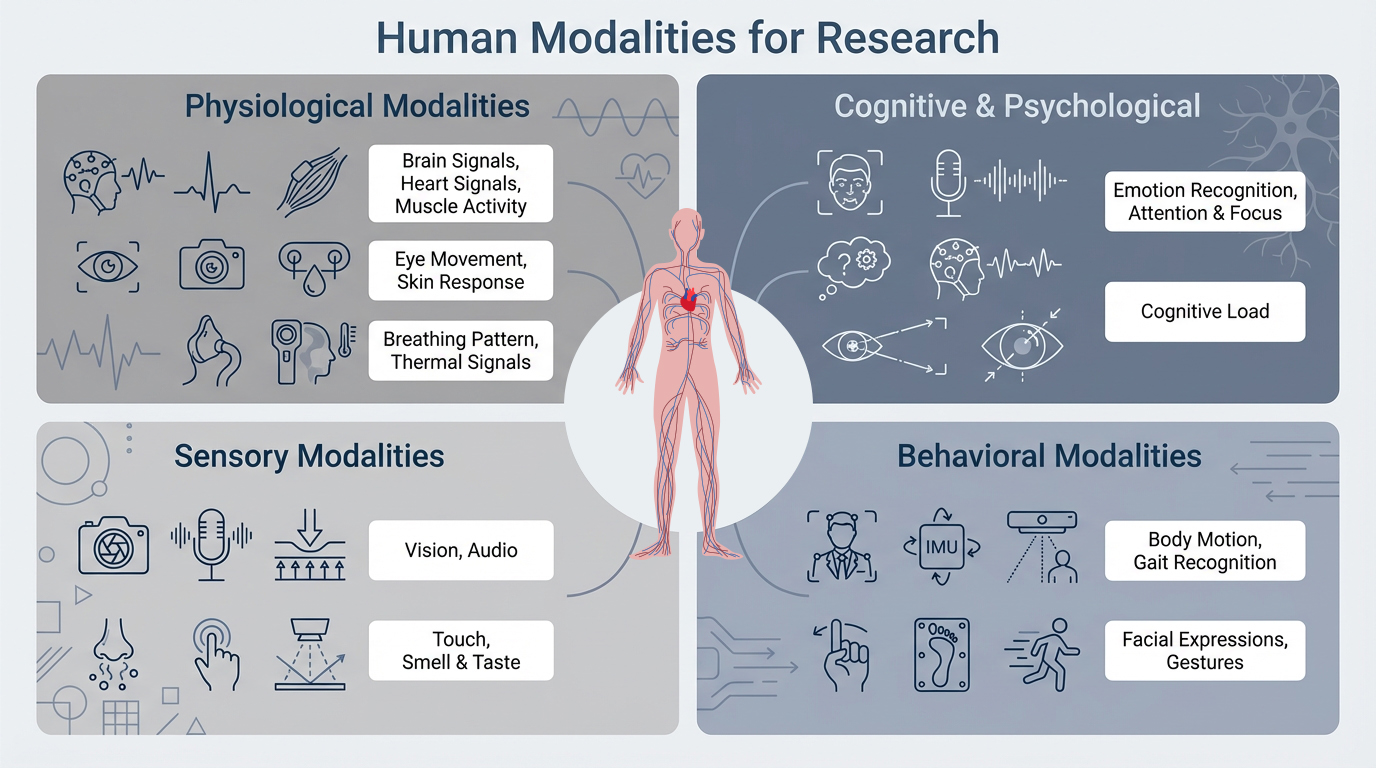
What is Multimodal AI?

Imagine watching a movie with the sound turned off. You see the action, but you miss the emotion in the voices. Now imagine the sound is on, but the picture is blurry. You hear the story, but you miss the expressions.
Multimodal AI is the science of putting those pieces back together. It's not just about a computer "reading text" or "looking at a photo." It's about a system that can see your gestures, hear your tone of voice, and even understand your heartbeat all at the same time to get the "full picture" of what is happening.
This is the promise of Multimodal AI which the Technology Innovation Hub at IIT Mandi is trying to bring to reality.
Why does this lab exist?
Today most AI is trained on a single type of data at a time (for example only text or only images), which is not enough to understand complex human behaviour or real-world environments.
Properly collected multimodal data everything recorded at the same time and perfectly synchronized is rare and difficult to create, especially for Indian languages, faces, accents and daily situations.
The Multimodal Lab is a state-of-the-art research space dedicated to advancing human-centric data collection and AI innovation. At its core, the lab focuses on understanding human behavior and interaction by capturing data from multiple human-centric modalities.
A human subject takes the center stage within a specialized environment, where advanced sensors record subtle human expressions, gestures, poses, movements, and responses from various perspectives.

Volumetric Capture Rig
This specialized steel structure is the core hardware interface of our Multimodal Data Collection Lab. Designed for high-fidelity human-centric research, this "egg" shaped chassis is housed within an anechoic chamber to facilitate the simultaneous capture of synchronized video, spatial audio, and physiological data. By providing a stable, 360° mounting surface for 16 Blackmagic cameras and assorted sensors, the rig enables the creation of dense, multi-view datasets for advanced AI and 3D reconstruction.
Core Benefits & Unique Advantages
- Spherical Equidistant Geometry: The curved design ensures cameras at varying altitudes (face, torso, and legs) maintain a consistent focal distance from the subject. This symmetry simplifies camera calibration and ensures uniform image resolution across the entire body.
- 360° Multi-Tiered Perspective: The frame supports high-density camera placement across three vertical zones. This eliminates "blind spots" and allows for the simultaneous capture of fine-grained micro-expressions, complex hand gestures, and full-body gait.
- Acoustically Optimized Profile: The slim-profile steel members minimize sound reflections within the anechoic environment. This allows for the mounting of high-sensitivity microphones in close proximity to the subject without compromising audio purity.
- Modular "Corner-Collapse" Versatility: The structure is engineered into four detachable quadrants. This allows the rig to be moved to the room's periphery when not in use, clearing the line-of-sight for ceiling-mounted OptiTrack systems to perform wide-area motion capture.
- Universal Sensor Integration: Beyond optics, the rig serves as a centralized chassis for biosensors (EMG/EDA) and localized lighting. This ensures all multimodal data streams—visual, auditory, and biological—are spatially anchored.

Why focus on India-Centric Data?

The Multimodal AI Lab at IIT Mandi will focus on creating the last two categories especially synchronized multimodal data collected actual Indian environments with Indians as subject. This will be India's first significant contribution to this critical global need.
Data does not exist to cater to the diversity of the Indian contexts, accents, expressions and daily life.
By building this lab, India can create AI systems that actually work well for Indians, rather than relying on foreign datasets that may not understand Indian faces, voices or situations.
What makes this lab unique?
The lab is building something similar in spirit to an "ImageNet"* for multimodality: a large, carefully designed collection of Indian multimodal data that others can use to create new AI tools.
A special egg-shaped camera setup with around 20 high quality cameras, lights, microphones and motion sensors captures very fine details of faces, voices and body movements at the same moment.
Dedicated spaces the Capture Room, Dark Room, UX Labs and Multi‑Sensor Room allow controlled experiments for vision, sound, user experience and body signals under many lighting and environmental conditions.
* ImageNet originated from a collaboration between Stanford and Princeton Universities, led by Stanford's Fei-Fei Li and Princeton's Kai Li, starting around 2008 to build a large visual database for computer vision research, using WordNet's structure to organize millions of images. The project became famous through the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which significantly advanced deep learning.
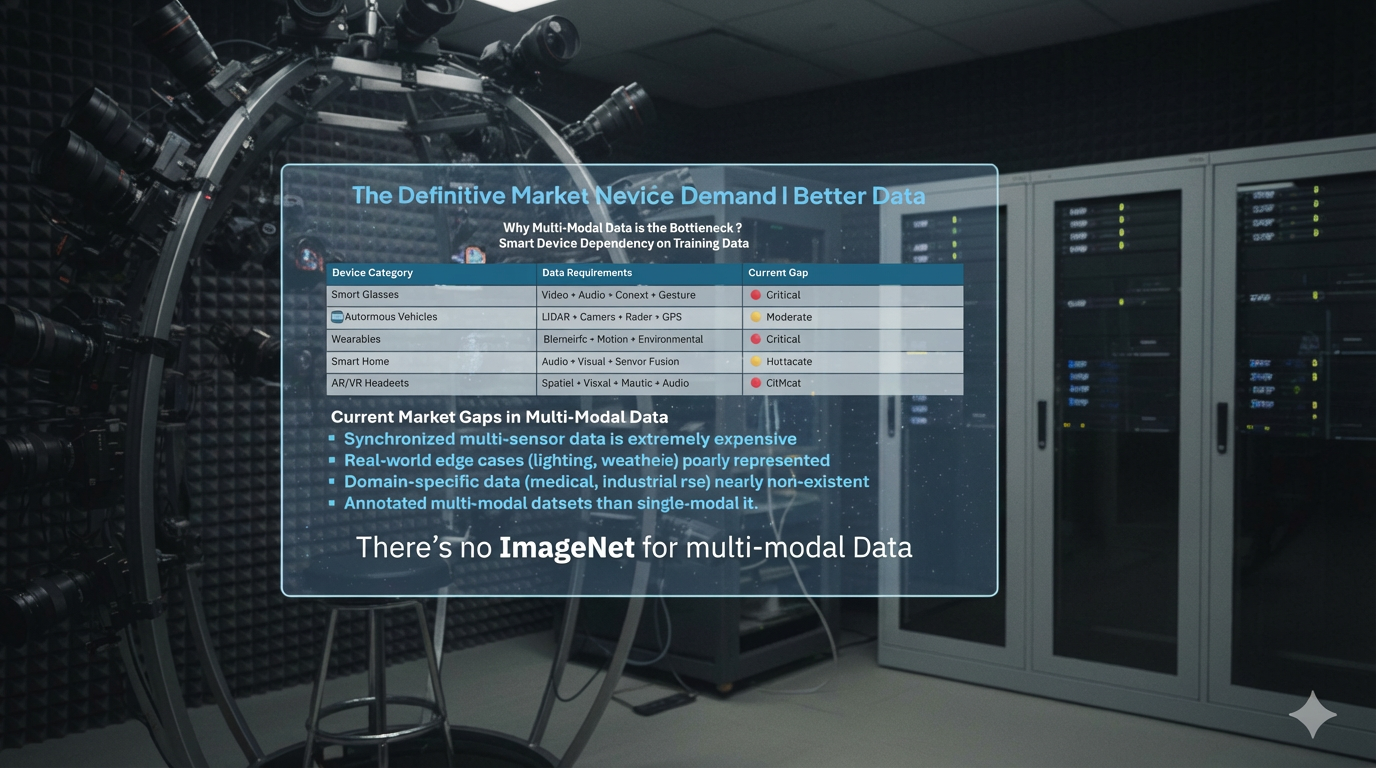
Explore the Lab
The Multimodal Data Collection Lab consists of controlled anechoic capture environment designed for high-fidelity, synchronized acquisition of human-centric data. The lab features a dedicated capture chamber equipped with a multi-camera, multi-sensor setup enabling 360-degree and 3D data capture of human subjects. High-speed cameras, precision microphones, and additional sensing modalities are spatially arranged and synchronized using advanced hardware-based techniques to ensure precise temporal alignment across data streams. This integrated infrastructure supports the creation of state-of-the-art multimodal and multiview datasets for industrial applications and the development of next-generation AI systems.

Advanced Infrastructure
- •High-speed cameras for capturing detailed visual data
- •Precision microphones for high-quality audio capture
- •Cutting-edge biosensing devices for physiological monitoring
- •Specialized hardware/equipment for precise synchronization
- •Temporal alignment at sub-millisecond accuracy
- •Comprehensive recording of emotional expressions and behavioral patterns

SOTA Data Capture Environment
- •High-end capture space for professional data acquisition
- •Advanced anechoic chamber for complete sound isolation
- •Specialized lighting infrastructure for varied conditions
- •Lighting scenarios from bright daylight to low-light settings
- •Controlled yet dynamic environment for human response studies
- •Ensures robustness and realism in datasets
High-Fidelity Multimodal Datasets
- •Acquisition of high-fidelity, real-world datasets
- •Comprehensive data covering emotional expressions and cognitive processes
- •Integrated capture of physiological and behavioral processes
- •Rigorously curated and systematically annotated datasets
- •Serve as ground truth for next-generation AI models
- •Enable advancements in emotion analysis and HCI
Industry Applications
Translating Multimodal Intelligence into Real-World Impact

Robotics & Intelligent Automation
Use Cases:
- •3D perception and scene understanding
- •Human–object interaction modeling
- •Robot learning through human demonstrations

Product Visualization & Virtual Commerce
Use Cases:
- •Novel view synthesis for products
- •3D product rotation and visualization
- •Virtual try-on and immersive product demos

Media, Entertainment & Digital Content
Use Cases:
- •3D human reconstruction for animation and VFX
- •Motion capture–driven character animation
- •Photorealistic digital humans and avatars

Healthcare, Rehabilitation & Assistive Technologies
Use Cases:
- •Motion tracking for physical rehabilitation
- •Cognitive–motor behavior analysis using EEG
- •Assistive AI systems for motor-impaired users
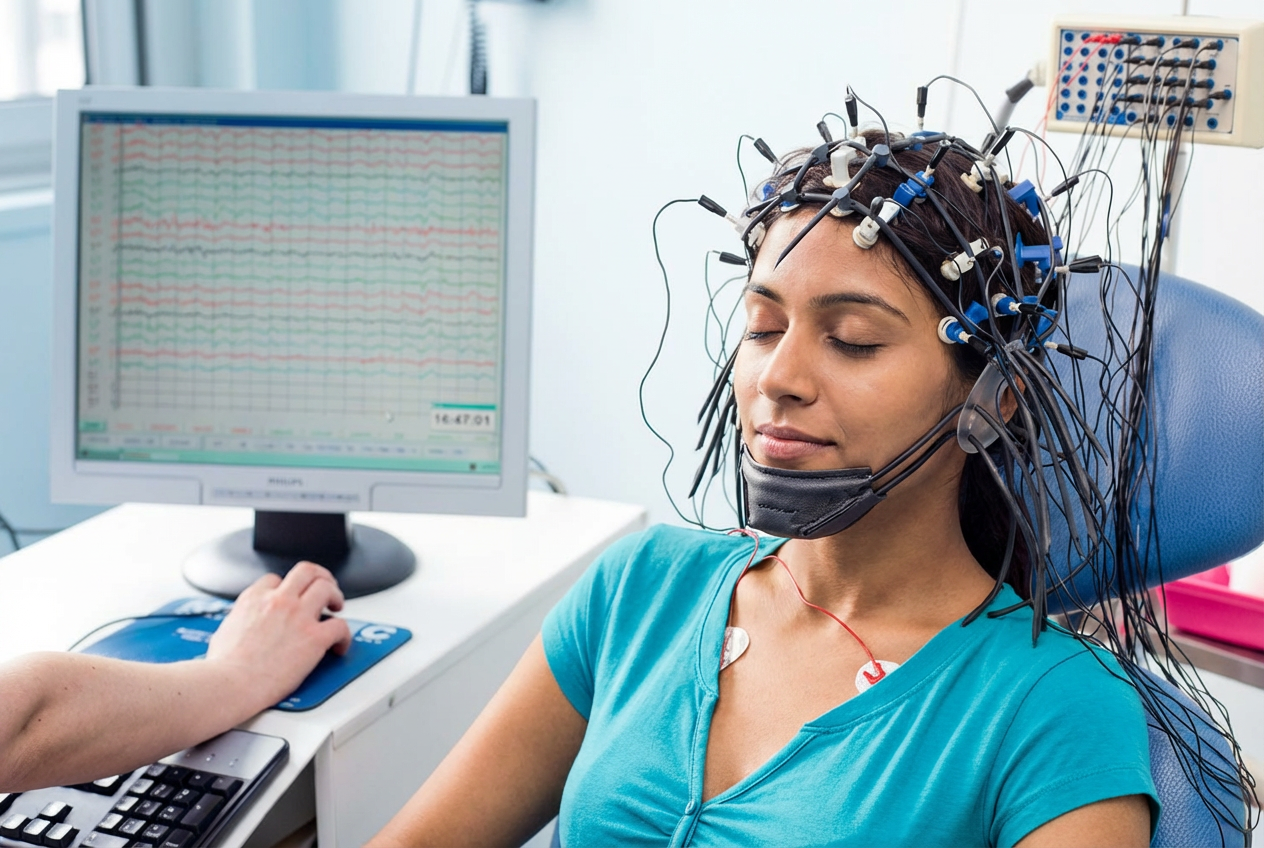
Neurological Health & Cognitive Monitoring
Use Cases:
- •Early detection of neurological disorders (Parkinson's, Alzheimer's)
- •Speech, facial, and motor behavior analysis for cognitive assessment
- •Multimodal biomarker discovery using synchronized signals

AR/VR/XR & Metaverse Applications
Use Cases:
- •Immersive interaction capture
- •Real-time avatar embodiment
- •Spatial mapping and localization

Surveillance & Security Intelligence
Use Cases:
- •Detection of abnormal human behavior through multimodal analysis of movement, posture, and gestures
- •Audio–visual threat assessment using voice stress, aggression cues, and activity recognition
- •Face–voice association and identity-aware behavior analysis for enhanced situational awareness
Team

Supported By

The Department of Science and Technology (DST), Government of India, serves as the nodal agency for strengthening the nation's innovation landscape by providing financial support through grants-in-aid for research infrastructure and scholarships, alongside strategic support by formulating national S&T policies and coordinating cross-sectoral missions to address future demands.
The Multimodal AI Lab being established at IIT Mandi campus by the Technology Innovation Hub has been supported through the grant provided under the NMICPS, in the area of Human-Centred AI.
Key demonstrations of this dual support include:
The department identifies "gap areas" in science and technology and seeds futuristic fields to align scientific progress with national socio-economic priorities.
We are extremely grateful to the leadership at DST which has supported us in this ambitious venture.
Meet the Minister

Dr Jitendra Singh
Minister of State (Independent Charge) for Science and Technology
Meet the Secretary

Prof. Abhay Karandikar
Secretary to the Government of India, Department of Science & Technology
Meet the HOD

Dr. Ekta Kapoor
Head of Scientific Divisions(HOD), Frontier and Futuristic Technologies (FFT) Division
The MI-RA (Multimodal Intelligence for Real-World Applications) Lab at IIT Mandi was formally inaugurated on 30 March 2026 by Padma Bhushan Kris Gopalakrishnan, Co-Founder of Infosys, Chairman of Axilor Ventures, and Chairman of the Mission Governing Board, NM-ICPS, marking a significant milestone in advancing industry-ready, human-centric AI research in India.




News+Updates
Let's share the stories of the Multimodal AI Lab's transformative breakthroughs where the convergence of audio, vision, and haptic to create technologies that enhance human capability and enable inclusive progress.
LinkedIn Post
Feb 19, 2026
Sovereignty Cannot Be Solitude
A perspective on sovereign AI and why openness (open source, open weights, open standards, and open infrastructure) matters as multimodal systems reshape national capability.
LinkedIn Post
Mar 9, 2026
Total Intelligence: Why Multimodal AI is the new AI reality?
An overview of why multimodal intelligence is becoming central to next-generation AI, covering synchronization, sensor fusion, and cross-modal learning.
LinkedIn Post
Mar 26, 2026
The System 3 Trap: Can Multimodal AI Restore Human Conscience?
A reflection on “Artificial Cognition” and the risks of over-trusting fluent AI outputs, with multimodal guardrails that keep humans in the loop for high-stakes decisions.
LinkedIn Post
Recent
Multimodal AI Research
Exploring the frontiers of multimodal AI research at IIT Mandi iHub. Our team is working on cutting-edge technologies that combine vision, audio, and haptic modalities.
LinkedIn Post
Recent
Multimodal AI Hackathon
Exciting times at the Multimodal AI Hackathon! Students and researchers coming together to build innovative AI solutions.
LinkedIn Post
Recent
Navigating Numbers and Narratives
Understanding the intersection of data science and storytelling in multimodal AI applications.
LinkedIn Post
Recent
Translational Research
Bridging the gap between academic research and real-world applications in multimodal AI.
LinkedIn Post
Recent
AI Generated Content
Exploring the capabilities and implications of AI-generated content in multimodal systems.
Contact Us
Get in touch with us for inquiries, collaborations, or any questions about our research.
Address
IIT Mandi iHub and HCi Foundation, North Campus, VPO Kamand, District Mandi, Himachal Pradesh, India - 175075